第五节:OpenCompass 大模型评测
by OpenCompass 核心开发者 曹茂松
文档 视频
算力平台ID: 25940
只经过预训练的基座模型 vs 经过SFT或RHF的对话模型
客观评测(rule-based) vs 主观评测(人工评价or模型评价)
基于prompt engineering去测试模型对于prompt的敏感性,鲁棒性

OpenCompass提供设计一套全面、高效、可拓展的大模型评测方案,对模型能力、性能、安全性等进行全方位的评估。

MMBench 多模态评测、LawBench、MedBench
OpenCompass采用提示词工程 (prompt engineering)和语境学习(in-context learning)进行客观评测。
在具体开展主观评测时,OpenComapss采用单模型回复满意度统计和多模型满意度比较两种方式开展具体的评测工作。
在 OpenCompass 中评估一个模型通常包括以下几个阶段:配置 -> 推理 -> 评估 -> 可视化。
配置:配置整个评估过程,选择要评估的模型和数据集。此外,还可以选择评估策略、计算后端等,并定义显示结果的方式。
推理阶段主要是让模型从数据集产生输出,而评估阶段则是衡量这些输出与标准答案的匹配程度。
实践
安装OpenCompass,准备数据集
scp -P35371 -o StrictHostKeyChecking=no -v opencompass-main.zip root@ssh.intern-ai.org.cn:/root
git clone https:
pip install -e
启动评测
python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
python run.py configs/eval_demo.py
配置文件通过 继承机制 引入所需的数据集和模型配置,并以所需格式组合 datasets 和 models 字段
数据集配置通常有两种类型:'ppl' 和 'gen',分别指示使用的评估方法。其中 ppl 表示辨别性评估,gen 表示生成性评估。
作业
基础作业
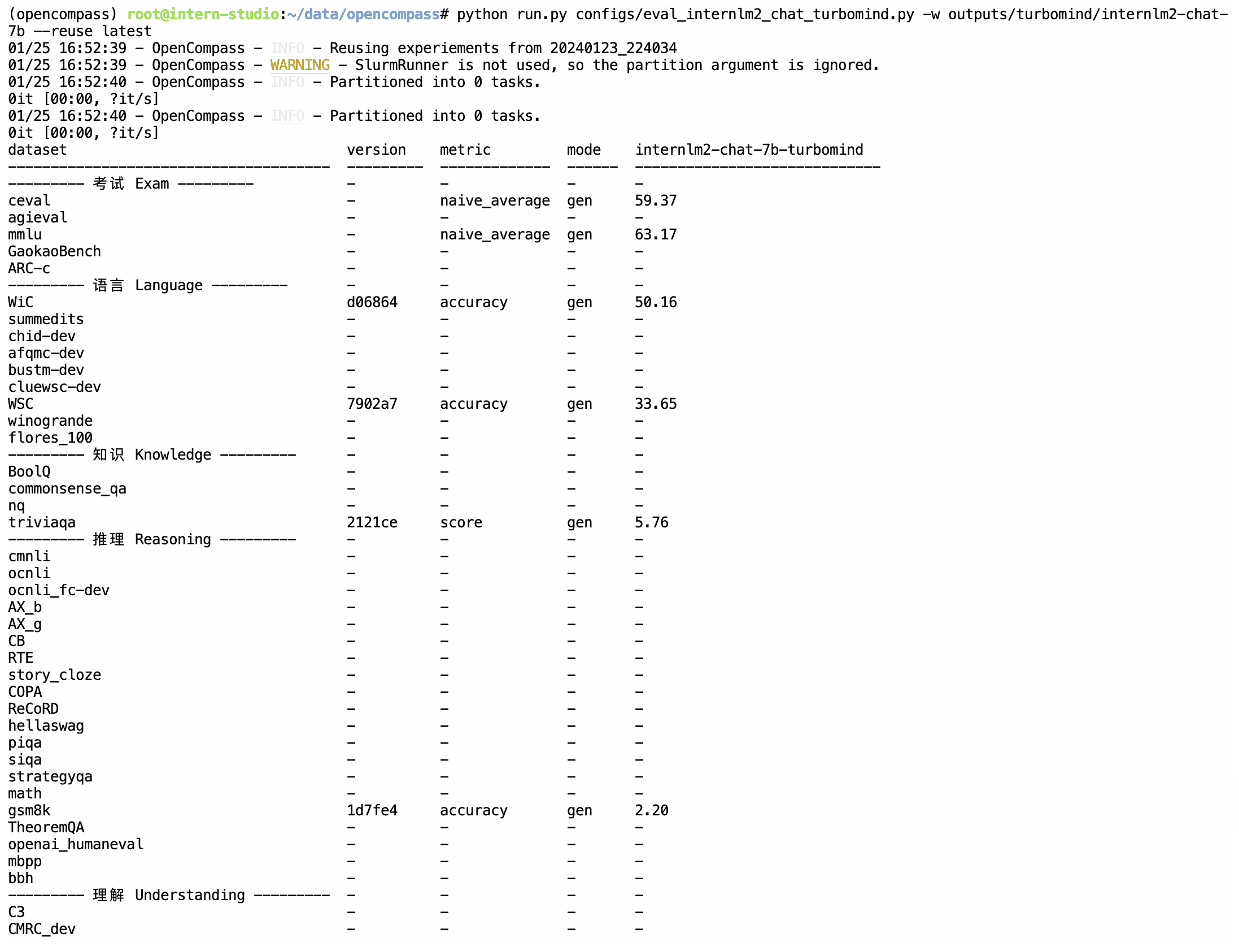
使用 OpenCompass 评测 InternLM2-Chat-7B 模型在 C-Eval 数据集上的性能
python run.py --datasets ceval_gen --hf-path internlm/internlm2-chat-7b --tokenizer-path internlm/internlm2-chat-7b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
进阶作业
使用 OpenCompass 评测 InternLM2-Chat-7B 模型使用 LMDeploy 0.2.0 部署后在 C-Eval 数据集上的性能
huggingface-cli download --resume-download internlm/internlm2-chat-7b --local-dir /root/data/model/Shanghai_AI_Laboratory/internlm2-chat-7b
pip install 'lmdeploy[all]==v0.2.0'
lmdeploy lite auto_awq /root/data/model/Shanghai_AI_Laboratory/internlm2-chat-7b/ --w-bits 4 --w-group-size 128 --work-dir ./quant_output
lmdeploy convert internlm2-chat-7b ./quant_output/ --model-format awq --group-size 128
#wrong
准备好测试配置文件configs/eval_internlm2_chat_turbomind.py
from mmengine.config import read_base
from opencompass.models.turbomind import TurboMindModel
with read_base():
# choose a list of datasets
from .datasets.mmlu.mmlu_gen_a484b3 import mmlu_datasets
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
from .datasets.SuperGLUE_WiC.SuperGLUE_WiC_gen_d06864 import WiC_datasets
from .datasets.SuperGLUE_WSC.SuperGLUE_WSC_gen_7902a7 import WSC_datasets
from .datasets.triviaqa.triviaqa_gen_2121ce import triviaqa_datasets
from .datasets.gsm8k.gsm8k_gen_1d7fe4 import gsm8k_datasets
from .datasets.race.race_gen_69ee4f import race_datasets
from .datasets.crowspairs.crowspairs_gen_381af0 import crowspairs_datasets
# and output the results in a choosen format
from .summarizers.medium import summarizer
datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')), [])
internlm_meta_template = dict(round=[
dict(role='HUMAN', begin='<|User|>:', end='\n'),
dict(role='BOT', begin='<|Bot|>:', end='<eoa>\n', generate=True),
],
eos_token_id=103028)
# config for internlm2-chat-7b
internlm2_chat_7b = dict(
type=TurboMindModel,
abbr='internlm2-chat-7b-turbomind',
path='internlm/internlm2-chat-7b',
engine_config=dict(session_len=2048,
max_batch_size=32,
rope_scaling_factor=1.0),
gen_config=dict(top_k=1,
top_p=0.8,
temperature=1.0,
max_new_tokens=100),
max_out_len=100,
max_seq_len=2048,
batch_size=32,
concurrency=32,
meta_template=internlm_meta_template,
run_cfg=dict(num_gpus=1, num_procs=1),
)
models = [internlm2_chat_7b]
在 OpenCompass 的项目目录下,执行如下命令
python run.py configs/eval_internlm2_chat_turbomind.py -w outputs/turbomind/internlm2-chat-7b