Jan 15, 2024

第五节:LMDeploy 大模型量化部署实践
by HuggingLLM 开源项目负责人 长琴
算力平台ID: 25940
模型部署
将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果
为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和硬件加速
云端、边缘计算端、移动端
CPU、 GPU、 NPU、 TPU 等

LMDeploy
LMDeploy 是 LLM 在英伟达设备上部署的全流程解决方案。包括模型轻量化、推理和服务。
written in Python & C++

量化
Weight FP16 + KV Cache FP16 vs Weight INT4 + KV Cache INT8
量化是一种以参数或计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。
计算密集 (compute-bound):推理的绝大部分时间消耗在数值计算上;针对计算密集场景,可以通过使用更快的硬件计算单元来提升计算速度,比如量化为 W8A8 使用 INT9 Tensor Core 来加速计算。
访存密集(memory-bound):推理时,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般是通过提高计算访存比来提升性能。
常见的 LLM 模型是 Decoder Only 架构。推理时大部分时间消耗在逐Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
KV Cache量化
在生成token时,需要历史key/value信息计算attention,可以将生成过程中的上下文 K 和 V 中间结果进行 INT8 量化,在使用时再反量化
计算minimax:给定输入样本在每一层不同位置处计算结果的统计情况
对于 Attention 的 K 和 V:取每个 Head 各自维度在所有Token的最大、最小和绝对值最大值。对每一层来说,上面三组值都是
(num_heads, head_dim)的矩阵。这里的统计结果将用于本小节的 KV Cache。对于模型每层的输入:取对应维度的最大、最小、均值、绝对值最大和绝对值均值。每一层每个位置的输入都有对应的统计值,它们大多是
(hidden_dim, )的一维向量,当然在 FFN 层由于结构是先变宽后恢复,因此恢复的位置维度并不相同。这里的统计结果用于下个小节的模型参数量化,主要用在缩放环节(回顾PPT内容)。
通过 minmax 获取量化参数:获取每一层的 K V 中心值(zp)和缩放值(scale)
修改 ./workspace/triton_models/weights/config.ini 文件中KV int8 开关,对应参数为quant_policy
默认值为 0,表示不使用 KV Cache,如果需要开启,则将该参数设置为 4。
Weight Only量化(W4A16量化)
W4A16中的A是指Activation,保持FP16,只对参数进行 4bit 量化。
LMDeploy 使用 MIT HAN LAB 开源的 AWQ 算法,量化为 4bit 模型【尽量不量化矩阵或张量计算时的小部分重要参数】
推理时,先把 4bit 权重反量化回 FP16(在 Kernel 内部进行,从Global Memory 读取时仍是 4bit),依旧使用的是 FP16 计算
相较于社区使用比较多的 GPTQ 算法,AWQ 的推理速度更快,量化的时间更短
推理引擎TurboMind
TurboMind 是一款关于 LLM 推理的高效推理引擎,基于英伟达的 FasterTransformer 研发而成。它的主要功能包括:LLaMa 结构模型的支持,persistent batch 推理模式和可扩展的 KV 缓存管理器。
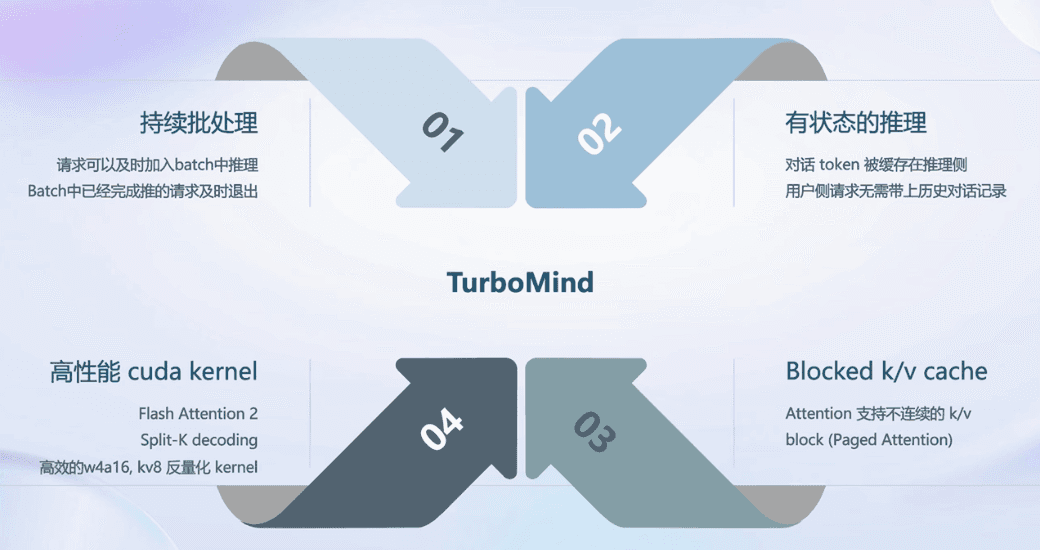
continuous batch:请求及时加入、及时退出
Persistent线程,请求队列 + Batch Slots
若 batch 中有空闲槽位,从队列拉取请求,尽量填满空闲槽位。若无,继续对当前 batch 中的请求进行forward
Batch每forward完一次,判断是否有request 推理结束。对于结束的request,发送结果,释放槽位

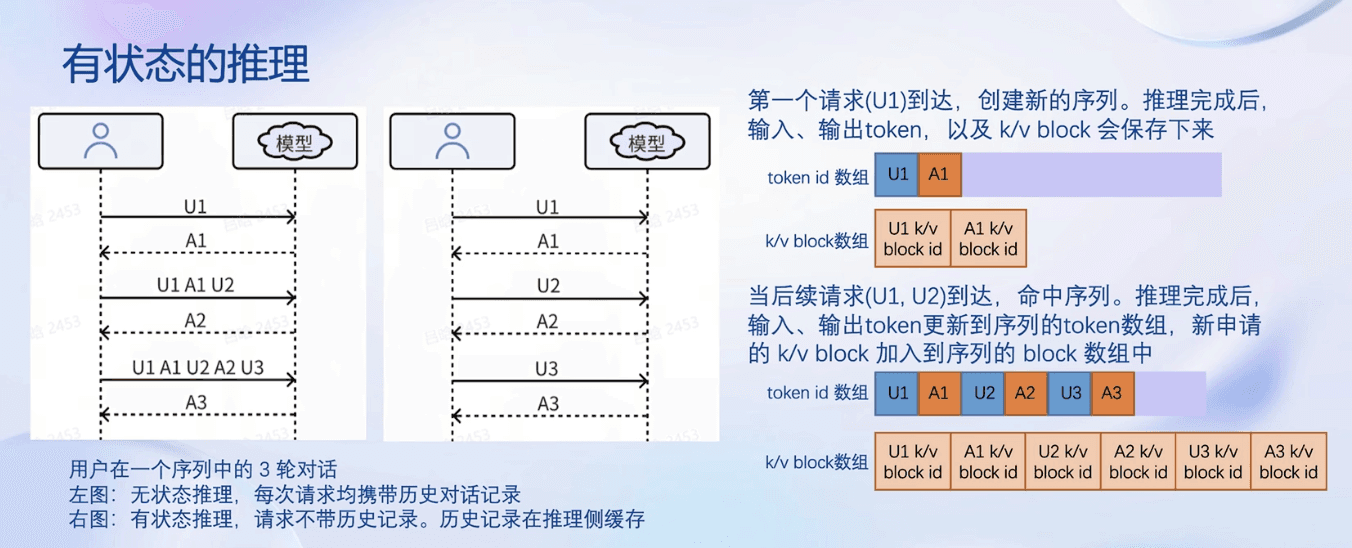
有状态推理:server端存储历史对话记录
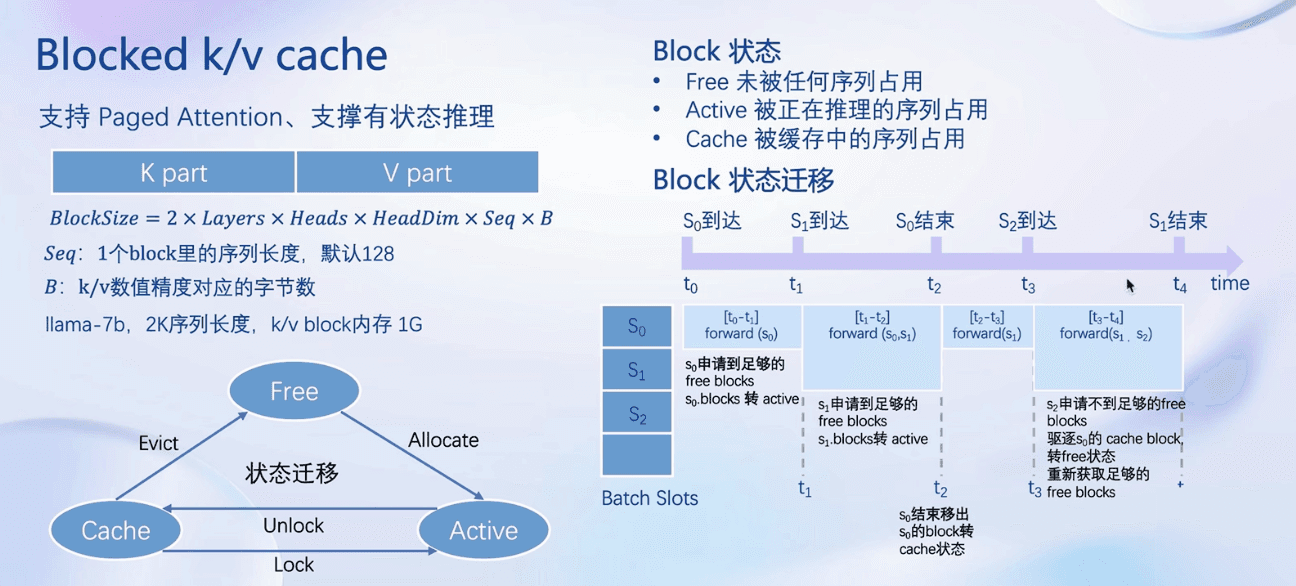
Blocked k/v cache
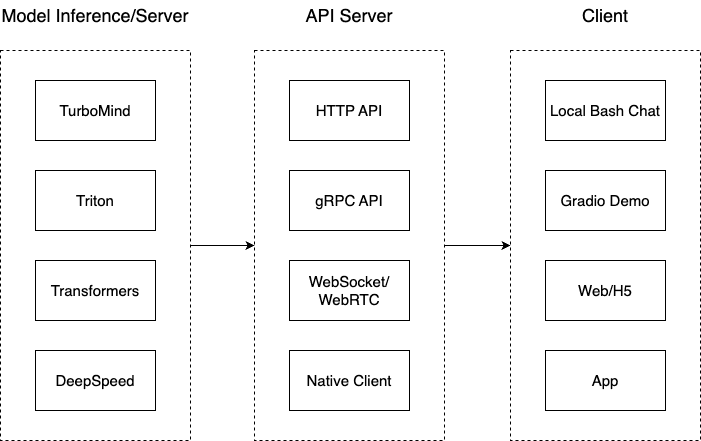
推理服务API Server
实践
pip install 'lmdeploy[all]==v0.1.0'
默认安装的是 runtime 依赖包,但这里还需要部署和量化,所以选择 [all]。
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 格式,目前支持在线转换和离线转换两种形式。在线转换可以直接加载 Huggingface 模型,离线转换需要先保存模型再加载。
”模型推理/服务“目前提供了 Turbomind 和 TritonServer 两种服务化方式。此时,Server 是 TurboMind 或 TritonServer,API Server 可以提供对外的 API 服务。
作业
基础作业
使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)


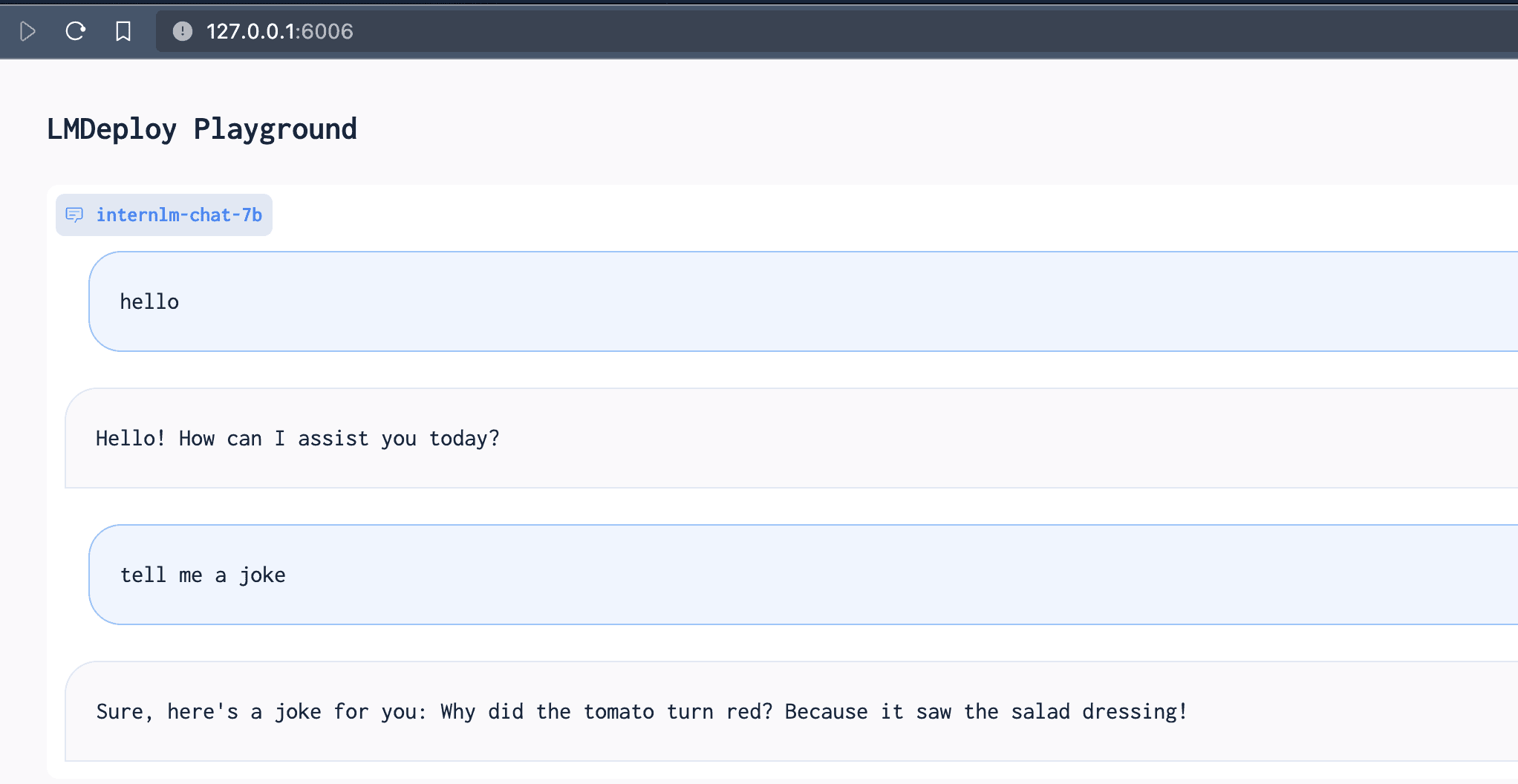

Python 直接与 TurboMind 进行交互,如下所示。
进阶作业(可选做)
将第四节课训练自我认知小助手模型使用 LMDeploy 量化部署到 OpenXLab 平台。
对internlm-chat-7b模型进行量化,并同时使用KV Cache量化,使用量化后的模型完成API服务的部署,分别对比模型量化前后(将 bs设置为 1 和 max len 设置为512)和 KV Cache 量化前后(将 bs设置为 8 和 max len 设置为2048)的显存大小。
模型量化前后对比
模型量化前
lmdeploy convert internlm-chat-7b /root/data/model/Shanghai_AI_Laboratory/interlm-chat-7b
得到workspace文件夹,配置./workspace/triton_models/weights/config.ini中session_len=512
lmdeploy serve api-server ./workspace/ --server_name 0.0.0.0 --server_port 23333 --instance_num 1 --tp 1

量化模型
lmdeploy lite calibrate \ --model /root/share/temp/model_repos/internlm-chat-7b/ \ --calib_dataset "c4" \ --calib_samples 128 \ --calib_seqlen 2048 \ --work_dir ./quant_output
lmdeploy lite auto_awq \ --model /root/share/temp/model_repos/internlm-chat-7b/ \ --w_bits 4 \ --w_group_size 128 \ --work_dir ./quant_output
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128 \
--dst_path ./workspace_quant
模型量化后
配置workspace_quant/triton_models/weights/config.ini中session_len=512
lmdeploy serve api-server ./workspace_quant/ --server_name 0.0.0.0 --server_port 23333 --instance_num 1 --tp 1

KV量化前
配置workspace_quant/triton_models/weights/config.ini中session_len=2048
lmdeploy serve api-server ./workspace_quant/ --server_name 0.0.0.0 --server_port 23333 --instance_num 8 --tp 1

KV量化后
lmdeploy lite kv_qparams \ --work_dir ./quant_output \ --turbomind_dir workspace_quant/triton_models/weights/ \ --kv_sym False \ --num_tp 1
配置workspace_quant/triton_models/weights/config.ini中quant_policy = 4
lmdeploy serve api-server ./workspace_quant/ --server_name 0.0.0.0 --server_port 23333 --instance_num 8 --tp 1

在自己的任务数据集上任取若干条进行Benchmark测试,测试方向包括:
(1)TurboMind推理+Python代码集成
(2)在(1)的基础上采用W4A16量化
(3)在(1)的基础上开启KV Cache量化
(4)在(2)的基础上开启KV Cache量化
(5)使用Huggingface推理