Jan 13, 2024

第四节:XTuner 大模型单卡低成本微调实战
by XTuner 社区贡献者 汪周谦【眼科AI系统的临床应用,多模态诊疗体系】
算力平台ID: 25940
Finetune
两种微调模式:增量预训练和指令跟随(指令微调)
指令微调=>instructed LLM
一问一答的数据形成对话模板
三种角色:system、user、assistant
各个大模型的对话模板关键词不同
训练时只对答案计算Loss
增量预训练微调
system、user留空,assistant是陈述句
三种微调算法:全参数微调(Full Finetuning【no adapters】)、LoRA、QLoRA
LoRA:Low-Rank Adaption of LLMs
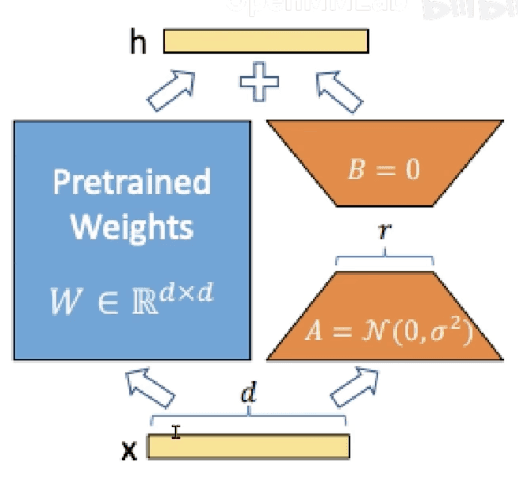
LLM 的参数量主要集中在模型中的 Linear,训练这些参数会耗费大量的显存
LoRA 通过在原本的 Linear 旁,新增一个支路,包含两个连续的小 Linear,新增的这个支路通常叫做 Adapter
Adapter 参数量远小于原本的 Linear,能大幅降低训练的显存消耗
Full Finetuning:需要在显存中加载整个模型+所有模型参数的优化器
LoRA:加载整个模型+LoRA部分参数优化器
QLoRA:4bit量化方式加载模型,参数优化器可在CPU和GPU间调度(事实上三种方法都可以,只是XTuner只做了QLoRA)
XTuner
书生浦语开发的大模型微调工具箱
XTuner数据引擎
原始问答对->格式化问答对->可训练语料
数据集映射函数、对话模板映射函数
多数据样本拼接(Pack DataSet),增强并行,充分利用GPU资源
优化技巧
Flash Attention 将 Attention 计算并行化,避免了计算过程中 Attention Score NXN的显存占用
DeepSpeed ZeRO【不是默认启动】
ZeRO 优化,通过将训练过程中的参数、梯度和优化器状态切片保存,能够在多GPU 训练时显著节省显存
除了将训练中间状态切片外,DeepSpeed 训练时使用 FP16 的权重,相较于 Pytorch 的AMP 训练,在单 GPU 上也能大幅节省显存
实战
info: Ubuntu 20.04, CUDA 11.7, CuDNN8.5-NCCL2.12, conda
resource: A100(1/4)
用MS-Agent数据集微调,赋予LLM Agent能力
本质是告诉LLM什么时候调用插件
MSAgent数据集每条样本包含一个对话列表 (conversations),其里面包含了 system、 user、 assistant 三种字段。其中:
system:表示给模型前置的人设输入,其中有告诉模型如何调用插件以及生成请求
e.g. 可以调用xx插件
user:表示用户的输入 prompt,分为两种,通用生成的prompt和调用插件需求的 prompt
assistant: 为模型的回复。其中会包括插件调用代码和执行代码,调用代码是要 LLM 生成的,而执行代码是调用服务来生成结果的
serper提供API接口
作业
基础作业:
构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手,效果如下图所示,本作业训练出来的模型的输出需要将不要葱姜蒜大佬替换成自己名字或昵称!

进阶作业:
将训练好的Adapter模型权重上传到 OpenXLab、Hugging Face 或者 MoelScope 任一一平台。
已上传OpenXLab