Jan 7, 2024

第一节:书生·浦语大模型全链路开源体系
by 上海人工智能实验室 陈恺 课程网站
算力平台ID: 25940
大模型是发展通用人工智能的一个重要途径
2006年深度学习理论获得突破,一个专用模型解决一个特定问题,后逐渐发展为一个通用大模型应对多种任务、多种模态(语言、视觉等)
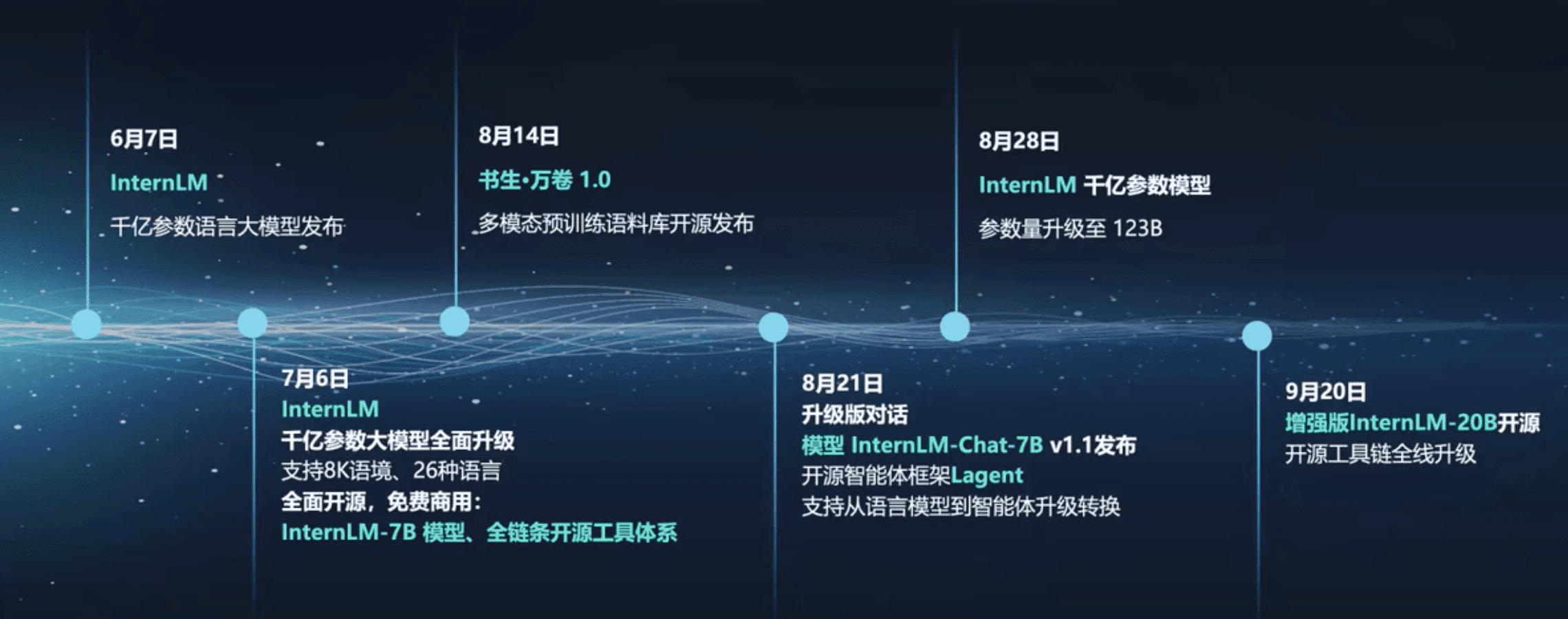
在此背景下,上海人工智能实验室推出书生·浦语大语言模型
从模型到应用
模型选型、续训/全参数微调/部分参数微调、构建智能体、模型评测、模型部署
若和环境交互,需要调用外部api或者与业务数据库交互,则要构建基于大模型的智能体agent,在业务场景中有更好表现
书生·浦语全链条开源开放体系

数据
书生·万卷,多模态(文本、图像-文本、视频)语料库 2TB
OpenDataLab开放数据平台,5400+数据集
预训练 InternLM Train
高可扩展:8卡到千卡
性能优化:Hybrid Zero技术
兼容主流:无缝接入HuggingFace技术生态
开箱即用:修改配置即可训练不同规格的语言模型
微调
增量续训,让基座模型学习某垂类领域知识
有监督微调,让模型学会理解和遵循各种指令,训练数据是高质量对话问答数据
全量参数微调,部分参数微调(LoRA、QLoRA算法)
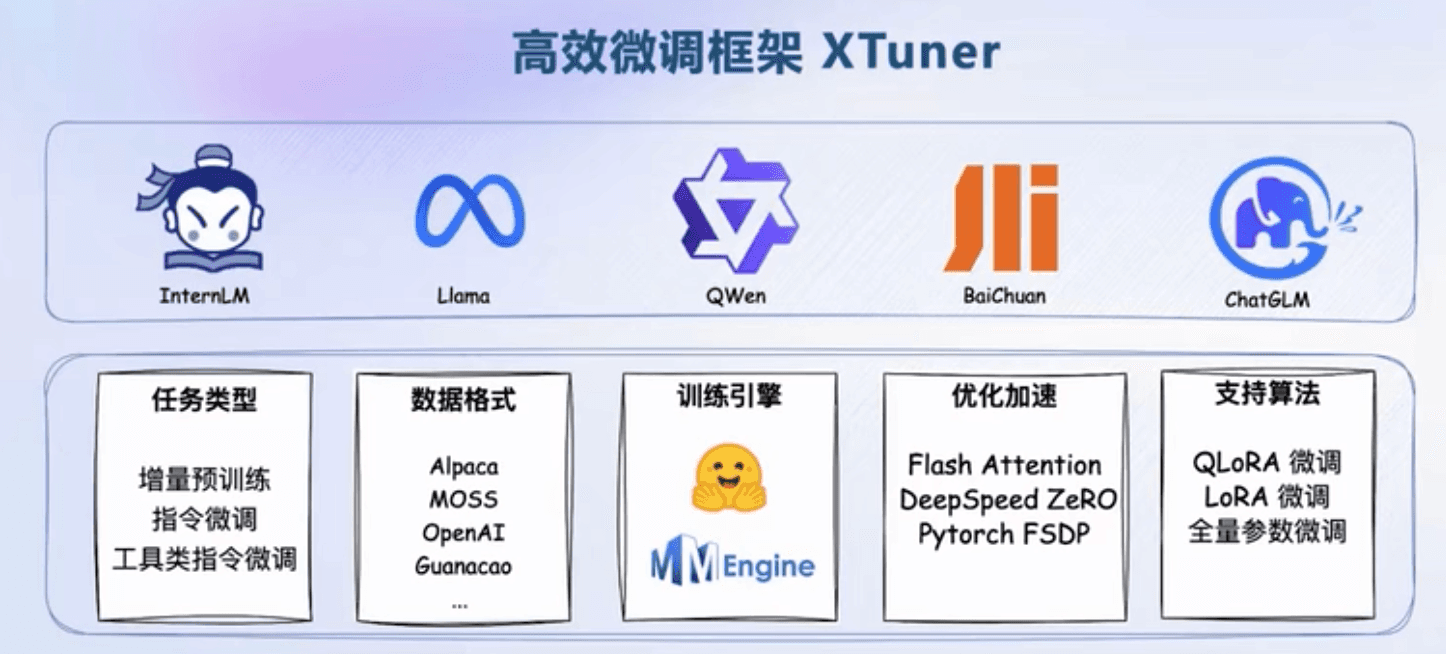
XTuner
适配多种生态,自动优化加速
适配多种硬件
NVIDIA消费级显卡 2080、3060-3090、4060-4090
NVIDIA数据中心 Tesla T4、V100、A10、A100、H100
极致显存优化
8GB显存上微调7B模型
评测体系
现有评测体系

OpenCompass
学科、语言、知识、理解、推理、安全

丰富的模型支持、分布式高效评测、便捷的数据集接口、敏捷的能力迭代

部署
大模型特点:内存开销巨大、动态shape(请求数、token不定)、模型结构相对简单(基于transformer,大部分decoder-only)
带来的挑战:低存储设备上部署、推理时token生成速度与动态shape造成的推理间断、提升吞吐量与平均响应时间性能
解决方案:模型并行、低比特量化、Attention优化、计算和访存优化、Continuous Batching
LMDeploy 提供大模型在GPU上部署的全流程解决方案
模型轻量化(4bit权重量化、8bit k/v量化)、推理(基于turbomind、pytorch推理引擎)、服务(openai server、gradio、trition inference server)

智能体
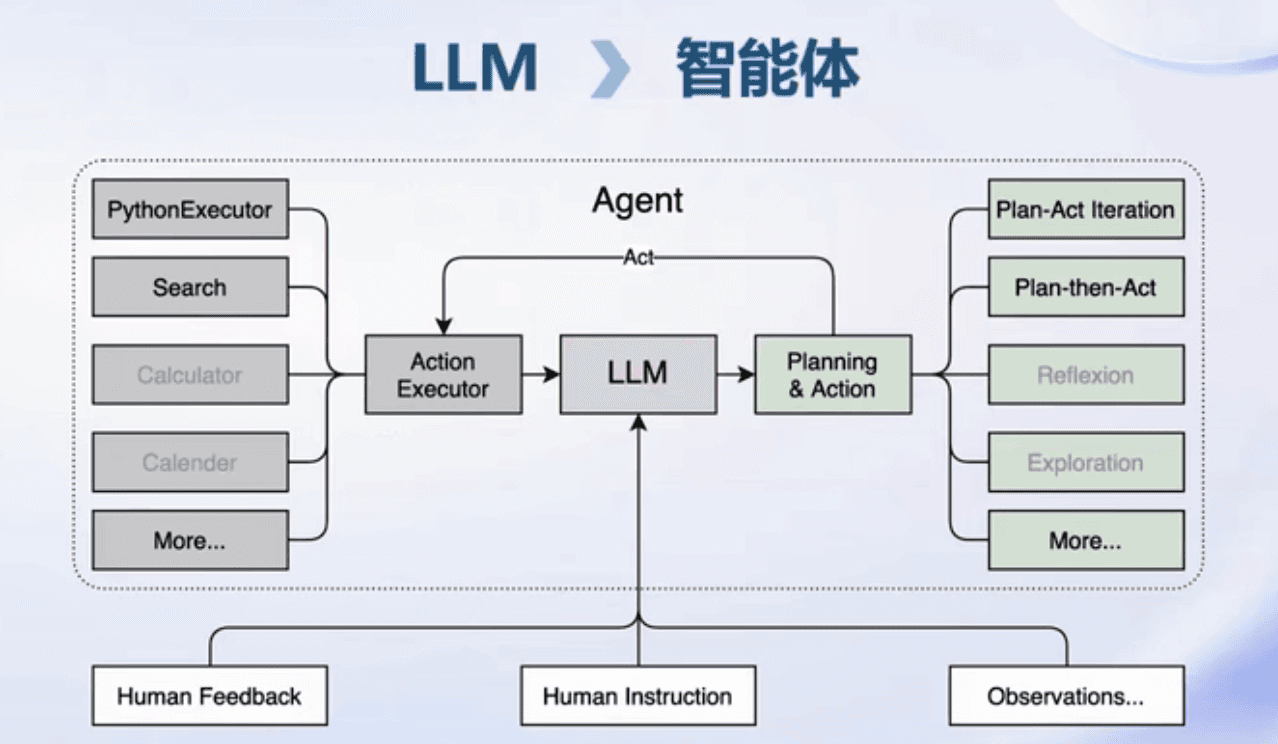
Lagent 智能体搭建框架
支持不同类型 ReAct、ReWoo、AutoGPT 执行逻辑Pipeline
支持GPT、InternLM、Hugging Face Transformers、Llama大语言模型
支持不同工具:AI工具、能力拓展(搜索、代码解释器)、Rapid API
AgentLego 给大模型提供工具集合
调用工具完成任务

支持多个主流智能体系统(LangChain、Transformers Agents、Lagent)、一键式远程工具部署